structmalloc_state { /* Serialize access. */ __libc_lock_define (, mutex); /* Flags (formerly in max_fast). */ int flags; /* Set if the fastbin chunks contain recently inserted free blocks. */ /* Note this is a bool but not all targets support atomics on booleans. */ int have_fastchunks;//glibc2.27以下没有 /* Fastbins */ mfastbinptr fastbinsY[NFASTBINS]; /* Base of the topmost chunk -- not otherwise kept in a bin */ mchunkptr top; /* The remainder from the most recent split of a small request */ mchunkptr last_remainder; /* Normal bins packed as described above */ mchunkptr bins[NBINS * 2 - 2]; /* Bitmap of bins */ unsignedint binmap[BINMAPSIZE]; /* Linked list */ structmalloc_state *next; /* Linked list for free arenas. Access to this field is serialized by free_list_lock in arena.c. */ structmalloc_state *next_free; /* Number of threads attached to this arena. 0 if the arena is on the free list. Access to this field is serialized by free_list_lock in arena.c. */ INTERNAL_SIZE_T attached_threads; /* Memory allocated from the system in this arena. */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
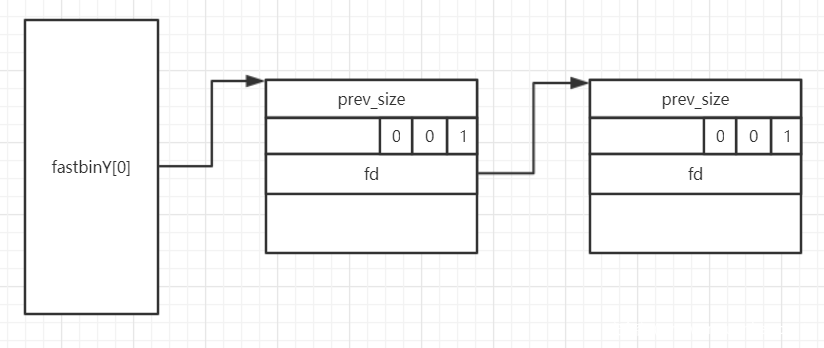
//glibc-2.26/malloc/malloc.c structmalloc_chunk { INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */ structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk; /* Only used for large blocks: pointer to next larger size. */ structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
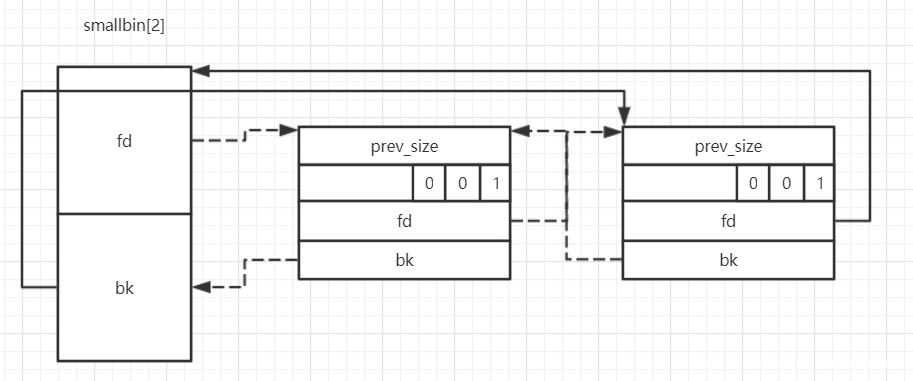
接着是当前堆块的 size,然后有两个指针,由于各种 bin 的存在,当堆块被释放后会进入对应的缓冲区中,并且以链表的形式存在,这里的 fd 和 bk 就是链表的前向后向指针,最后两个也是指针,但是它们只会出现在 largebin chunk 中,具体会在后面提到。
一个堆块可能会是下面的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk, if unallocated (P clear) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk, in bytes |A|M|P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | User data starts here... . . . . (malloc_usable_size() bytes) . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | (size of chunk, but used for application data) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of next chunk, in bytes |A|0|1| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
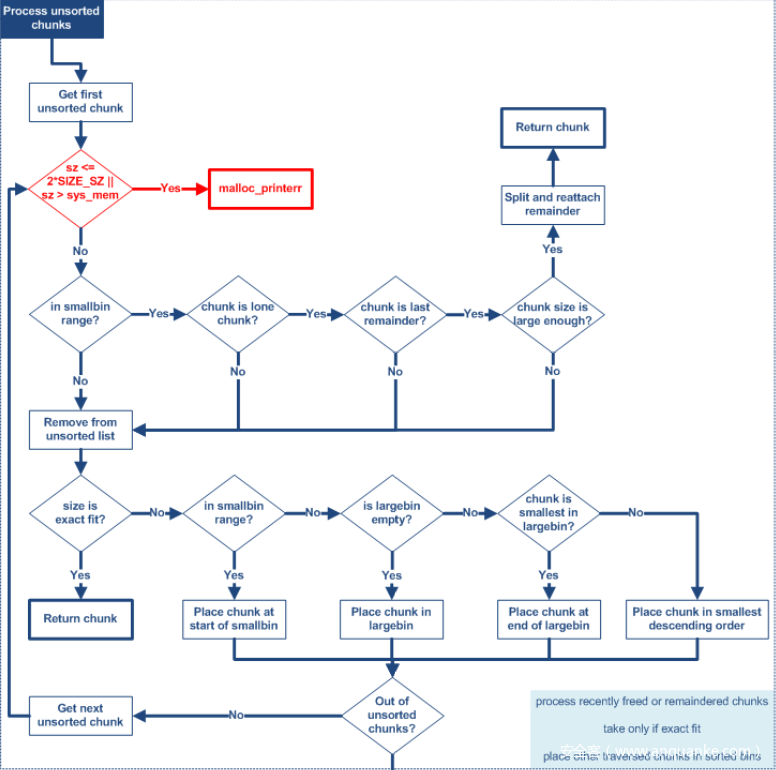
Unsorted chunks All remainders from chunk splits, as well as all returned chunks, are first placed in the "unsorted" bin. They are then placed in regular bins after malloc gives them ONE chance to be used before binning. So, basically, the unsorted_chunks list acts as a queue, with chunks being placed on it in free (and malloc_consolidate), and taken off (to be either used or placed in bins) in malloc. The NON_MAIN_ARENA flag is never set for unsorted chunks, so it does not have to be taken into account in size comparisons.
victim = _int_malloc (ar_ptr, bytes); //调用_int_malloc分配chunk /* Retry with another arena only if we were able to find a usable arena before. */ if (!victim && ar_ptr != NULL) //分配失败就找其他分配区 { LIBC_PROBE (memory_malloc_retry, 1, bytes); ar_ptr = arena_get_retry (ar_ptr, bytes); //retry函数中将之前的分配区解锁新的分配区加锁 victim = _int_malloc (ar_ptr, bytes); }
if (ar_ptr != NULL) //分配结束 分配区解锁 (void) mutex_unlock (&ar_ptr->mutex);
... /* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size traps (returning 0) request sizes that are so large that they wrap around zero when padded and aligned. */
checked_request2size (bytes, nb); ...
若没有可用的分配区,则调用 sysmalloc 用 mmap 或者 brk 获取一块。
1 2 3 4 5 6 7 8 9 10 11
... /* There are no usable arenas. Fall back to sysmalloc to get a chunk from mmap. */ if (__glibc_unlikely (av == NULL)) { void *p = sysmalloc (nb, av); if (p != NULL) alloc_perturb (p, bytes); return p; } ...
... /* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */
... /* If a small request, check regular bin. Since these "smallbins" hold one size each, no searching within bins is necessary. (For a large request, we need to wait until unsorted chunks are processed to find best fit. But for small ones, fits are exact anyway, so we can check now, which is faster.) */
if (in_smallbin_range (nb)) //判断size { idx = smallbin_index (nb); //获取idnex bin = bin_at (av, idx); //获取bins[index]
... /* If this is a large request, consolidate fastbins before continuing. While it might look excessive to kill all fastbins before even seeing if there is space available, this avoids fragmentation problems normally associated with fastbins. Also, in practice, programs tend to have runs of either small or large requests, but less often mixtures, so consolidation is not invoked all that often in most programs. And the programs that it is called frequently in otherwise tend to fragment. */
/* Process recently freed or remaindered chunks, taking one only if it is exact fit, or, if this a small request, the chunk is remainder from the most recent non-exact fit. Place other traversed chunks in bins. Note that this step is the only place in any routine where chunks are placed in bins.
The outer loop here is needed because we might not realize until near the end of malloc that we should have consolidated, so must do so and retry. This happens at most once, and only when we would otherwise need to expand memory to service a "small" request. */
... /* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */
/* maintain large bins in sorted order */ if (fwd != bck) //largebin不为空则按照size将victim插入largebin的size link中 { /* Or with inuse bit to speed comparisons */ size |= PREV_INUSE; /* if smaller than smallest, bypass loop below */ assert ((bck->bk->size & NON_MAIN_ARENA) == 0); if ((unsignedlong) (size) < (unsignedlong) (bck->bk->size)) { fwd = bck; bck = bck->bk;
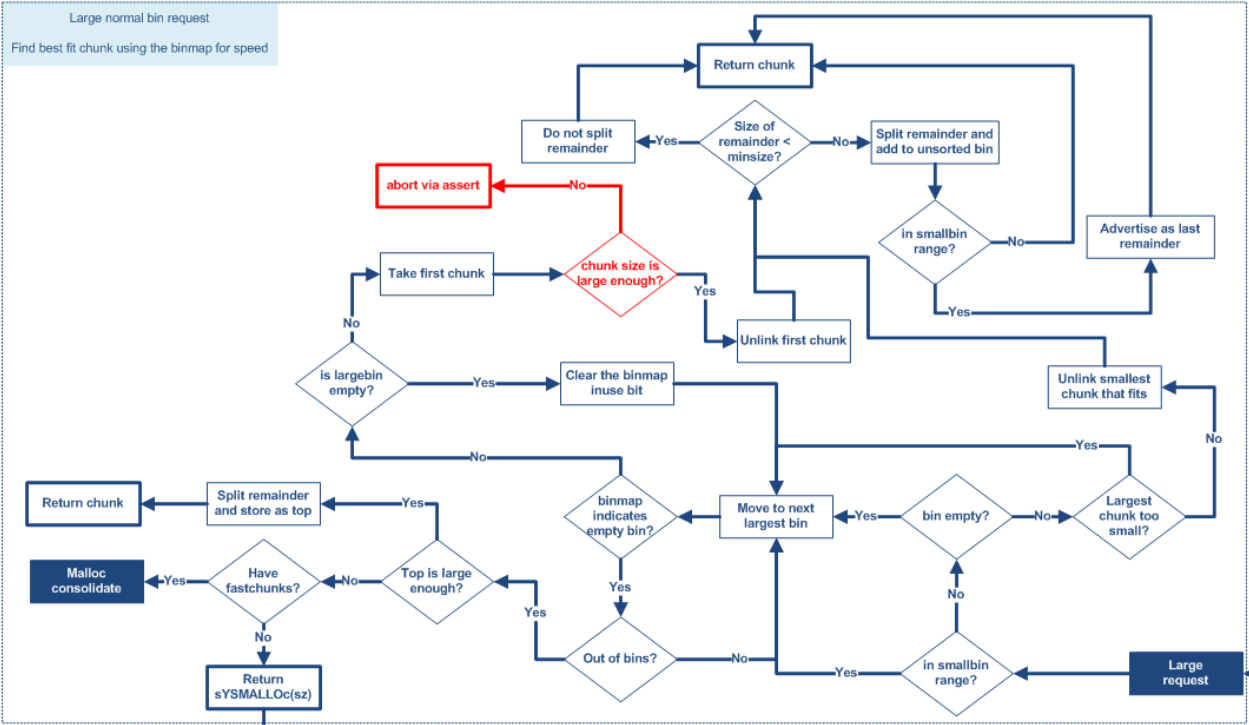
... /* If a large request, scan through the chunks of current bin in sorted order to find smallest that fits. Use the skip list for this. */
if (!in_smallbin_range (nb)) //判断是否属于smallbin { bin = bin_at (av, idx); //获取largebin,idx在之前判断size属于largebin时被赋值
/* skip scan if empty or largest chunk is too small */ if ((victim = first (bin)) != bin && //bin非空 (unsignedlong) (victim->size) >= (unsignedlong) (nb)) //size小于链表中的max size { victim = victim->bk_nextsize; //从最小的chunk开始 while (((unsignedlong) (size = chunksize (victim)) < (unsignedlong) (nb))) //按照size从小到大依次寻找 victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ if (victim != last (bin) && victim->size == victim->fd->size) //避免删掉作为长度标识的chunk victim = victim->fd;
/* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected. The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */
++idx; bin = bin_at (av, idx); block = idx2block (idx); map = av->binmap[block]; bit = idx2bit (idx);
for (;; ) { /* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ((map = av->binmap[block]) == 0); //遍历binmap表找有空闲chunk的largebin
bin = bin_at (av, (block << BINMAPSHIFT)); bit = 1; }
/* Advance to bin with set bit. There must be one. */ while ((bit & map) == 0) { bin = next_bin (bin); bit <<= 1; assert (bit != 0); }
/* Inspect the bin. It is likely to be non-empty */ victim = last (bin);
/* If a false alarm (empty bin), clear the bit. */ if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin (bin); bit <<= 1; }
else { size = chunksize (victim);
/* We know the first chunk in this bin is big enough to use. */ assert ((unsignedlong) (size) >= (unsignedlong) (nb));
remainder_size = size - nb;
/* unlink */ unlink (av, victim, bck, fwd);
/* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset (victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; }
use_top: /* If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations). We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise be exhausted by current request, it is replenished. (The main reason for ensuring it exists is that we may need MINSIZE space to put in fenceposts in sysmalloc.) */
/* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (have_fastchunks (av)) //不够但还有fastbins就整理fastbins再尝试 { malloc_consolidate (av); /* restore original bin index */ if (in_smallbin_range (nb)) idx = smallbin_index (nb); else idx = largebin_index (nb); }